目次
TweetXer:删除 X(旧Twitter) 上无法取消的转推
在 X 的旧帖子中经常会遇到这种情况:
如图所示,本应是绿色的“已转推”图标变成了灰色 (Grayed out),导致无法取消转推。
https://github.com/lucahammer/tweetXer
如果您想删除这类转推,可以使用名为 TweetXer 的 UserScript(用户脚本)。
准确地说,这是一个**可以删除包括转推在内的所有帖子**的脚本,由于以下原因,它的优点是运行起来非常方便。
- 无需 API Key
- 电脑版只需使用开发者工具即可运行
仅仅为了删除帖子而准备 API 环境是很麻烦的。
虽然也可以通过 Tampermonkey 在手机上运行,但出于以下原因,建议在电脑上操作。
- 需要下载文件较大的 X 全量数据
- 如果想删除特定的帖子,需要编辑 tweet-headers.js 文件
我写这篇文章是因为搜索“X 转推 无法取消”时,出来的都是些不相关的文章。
特别是那些说“有编辑记录就无法取消”的虚假文章。
明明没付费账号的帖子也变灰了,不知道在胡说什么。
使用方法
官方有说明和视频,这里简单总结一下:
- 从 X 下载全量数据
“设置” → “账户” → “下载数据归档”
- 解压下载的 ZIP 压缩包
-
等待 TweetXer 显示:“Select your tweet-headers.js from your Twitter Data Export to start the deletion of all your Tweets.”
- 通过 TweetXer 的“浏览”按钮加载解压后的 tweet-headers.js 文件
- 所有帖子将被删除
Tampermonkey 版的 TweetXer 启用时会强制跳转到主页,这是为了获取删除所需的信息,属于正常设定。
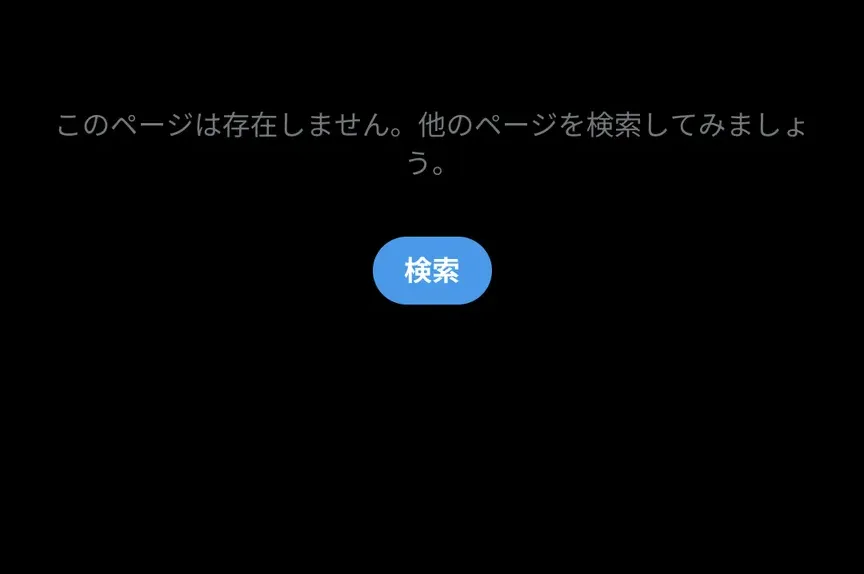
旧的转推已删除的截图。
实际上,我想很少有人愿意删除**所有**帖子,所以您可能需要编辑 tweet-headers.js。
因为涉及编辑 JSON 文件,所以如果想删除特定的帖子或转推会比较麻烦。
如果数量少,可以手动操作,但如果数量多,还是需要在电脑上使用 Python 等工具处理。
截至 2025 年 7 月,最新版 TweetXer 无法运行
Doesn't work, bar doesn't move and not tweets deleted · Issue #38 · lucahammer/tweetXer
已有上述 Issue 报告。
旧版本可以正常工作,所以在修复之前请使用这个版本。
无论如何都有可能无法运行
即使步骤完全相同,也有可能无法运行。
或者说运行成功的概率大概只有 1/5?
不知道是不是 X 的限制,在电脑的开发者工具中查看,大多数情况下都会返回 HTTP 状态码 400。
这并不是罕见的情况,所以请隔一段时间多试几次。
从仅包含要删除帖子 ID 的文件创建 tweet-headers.js 的 Python 脚本
几乎只能在电脑上执行,所以感兴趣的人可以阅读一下。
X 帖子的 URL 格式如下:
https://x.com/[username]/status/[1945123456789]
我编写了一个 Python 脚本,只要准备一个只写有这部分数字的文件,就可以生成 tweet-headers.js。
- 准备一个名为 `delete-ids.txt` 的文件,里面只写要删除帖子的末尾数字。
例如:
1945123456789
1946123456789
1947123456789
...
- 将以下 Python 文件和 `delete-ids.txt` 放在与 `tweet-headers.js` 相同的目录下。
- 执行 `python ./delete.py`。
只需以上操作,脚本就会根据帖子 ID 生成名为 `filtered-headers.js` 的文件,将其加载到 TweetXer 中即可。
import json
import re
from pathlib import Path
# 从文件中提取 tweet_id(支持 JSON 格式和纯数字行)
def load_ids_from_mixed_json(file_path):
id_set = set()
with open(file_path, encoding="utf-8") as f:
for line in f:
line = line.strip()
# 行中包含 JSON 的情况,如 {"tweet_id": "123456789"}
match = re.search(r'"tweet_id"s*:s*"(d+)"', line)
if match:
id_set.add(match.group(1))
# 行中仅为数字的情况
elif re.fullmatch(r"d{5,}", line): # 简单的位数限制
id_set.add(line)
return id_set
# 仅从 JS 文件中提取内容
def extract_json_array(file_path):
with open(file_path, encoding="utf-8") as f:
js = f.read()
match = re.search(r'=s*([s*{.*}s*]);?s*$', js, re.DOTALL)
if not match:
raise ValueError(f"Cannot parse JSON array from: {file_path}")
return json.loads(match.group(1))
# 读取数据
def load_tweet_headers(path):
return {item["tweet"]["tweet_id"]: item["tweet"] for item in extract_json_array(path)}
# 根据 id_set 筛选 header
def filter_headers(headers, id_set):
return [{"tweet": tweet} for id_, tweet in headers.items() if id_ in id_set]
# 执行
def main():
input_path = Path("delete-ids.txt")
headers_path = Path("tweet-headers.js")
output_path = Path("filtered-headers.js")
id_set = load_ids_from_mixed_json(input_path)
headers = load_tweet_headers(headers_path)
filtered = filter_headers(headers, id_set)
# 在开头添加 window.YTD.tweet_headers.part0 =
with open(output_path, "w", encoding="utf-8") as f:
f.write("window.YTD.tweet_headers.part0 = ")
json.dump(filtered, f, ensure_ascii=False, indent=2)
print(f"已提取 {len(filtered)} 条推文。")
if __name__ == "__main__":
main()